一句话导读:本文深入解析AI助手玩具的核心技术——智能体(Agent)与大模型(LLM),从市场痛点到底层原理,带你彻底搞懂这一热门赛道的技术逻辑,文末附高频面试题及答案。
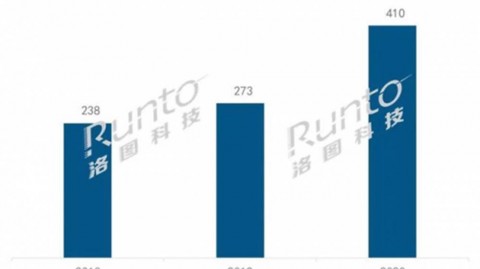
近年来,AI助手玩具从一个略带科幻色彩的概念,迅速成长为消费电子领域最热门的赛道之一。数据显示,2026年全球AI玩具市场预计攀升至300亿美元以上,其中陪伴类AI玩具在中国市场的规模正以年复合增长率超70%的速度爆发式增长--7。华为、字节跳动、京东等科技巨头竞相入局,CES 2026展会上AI陪伴机器人更是成为全场焦点-6。许多人只听说过“AI玩具”,却分不清“大模型”和“智能体”这两个核心概念有什么区别——面试时一问便露怯,项目中对技术选型也常常一头雾水。本文将围绕“AI助手玩具中的智能体(Agent)与大模型(LLM)”这条主线,从市场痛点切入,逐步解析概念、逻辑、代码示例与底层原理,助你建立完整的知识链路。

一、基础信息配置
目标读者:技术入门/进阶学习者、在校学生、面试备考者、AIoT相关开发工程师
文章定位:技术科普 + 原理讲解 + 代码示例 + 面试要点,兼顾易懂性与实用性
风格基调:条理清晰、由浅入深、语言通俗、重点突出
核心目标:让读者理解概念、理清逻辑、看懂示例、记住考点

二、痛点切入:为什么AI助手玩具需要专门的“大脑”架构?
先来看一段“典型”的AI助手玩具实现代码(简陋版):
传统玩具实现方式:一问一答 def handle_user_input(text): if "你好" in text: return "你好呀!" elif "叫什么" in text: return "我叫小智" elif "讲故事" in text: return "从前有座山..." else: return "我听不懂你在说什么"
这种“硬编码规则”的实现方式存在几个致命缺陷:
耦合高:每个功能都要手写if-else逻辑,功能越多代码越臃肿
扩展性差:新增一种交互场景(如猜谜、教英语)需要修改核心代码
维护困难:100个用户的问题组合可能产生1000种问法,规则无法覆盖
缺乏上下文记忆:玩具无法记住用户上一句说了什么,每次交互都是“失忆”状态
这些问题催生了对更智能解决方案的需求。随着大语言模型(Large Language Model,LLM)的成熟,开发者开始将LLM接入玩具,试图赋予其“思考”能力。单纯接入大模型又带来了新的问题:大模型只知道“回答问题”,不知道“玩具是谁、用户是谁、当前场景是什么”。于是,一个新的架构层——智能体(Agent) 应运而生。
三、核心概念讲解:智能体(Agent)
什么是智能体(Agent)?
标准定义:在人工智能领域,智能体(Agent)是指能够感知环境、自主决策并执行行动以实现特定目标的实体或软件模块。在AI助手玩具的上下文中,Agent是位于用户与大模型之间的调度与协调层。
拆解关键词
感知:Agent能够接收用户输入(语音转文字、触摸信号、动作感应等),同时能感知上下文环境(用户是谁、对话历史、当前场景模式)
决策:Agent根据输入和内置规则,判断应该调用哪个能力模块、是否需要调用大模型、调用哪种大模型
执行:Agent将决策结果转化为具体行动,如语音输出、控制玩具肢体动作、生成个性化内容
生活化类比
想象一个餐厅场景:大模型(LLM)就像是后厨的“全能厨师”——会做各种菜,但不会主动问你要吃什么,也不知道上菜规则。而智能体(Agent)就是“餐厅服务员”——负责点单、理解客人需求、把订单交给合适的厨师、再把菜端上来,还要记住这个客人的忌口偏好。
在AI助手玩具中,Agent正是那个“服务员”:它知道玩具的角色设定(比如一只会讲故事的兔子),知道当前用户是3岁的小朋友,会主动调用“教育启蒙”模块来回答问题,而不是机械地让大模型直接输出答案。
Agent的作用与价值
场景识别:自动判断当前是聊天模式、学习模式还是游戏模式
记忆管理:维护长期记忆和短期记忆,让玩具能够“记住”用户
安全防护:在请求进入大模型之前进行内容过滤,防止大模型输出不适合儿童的内容
成本控制:根据场景选择不同的模型策略(简单问题用小模型,复杂问题用大模型),降低API调用成本
四、关联概念讲解:大模型(LLM)
什么是大模型(LLM)?
标准定义:大语言模型(Large Language Model,LLM)是基于海量文本数据训练而成的深度学习模型,能够理解自然语言并生成连贯、相关的文本回复。常见的有DeepSeek、豆包、通义千问等。
它与Agent的关系
Agent与大模型是“调度者”与“执行者” 的关系:Agent负责决策“什么情况下调用大模型、调用哪个大模型”,大模型则负责完成Agent交办的具体生成任务。
对比:Agent vs LLM
| 维度 | Agent(智能体) | LLM(大语言模型) |
|---|---|---|
| 核心职能 | 调度、协调、记忆、安全 | 理解、推理、生成 |
| 是否需要网络 | 通常端侧部署 | 可云端/端侧 |
| 能否记住用户 | ✅ 内置记忆模块 | ❌ 无状态 |
| 能否控制肢体 | ✅ 可输出动作指令 | ❌ 仅输出文本 |
| 能否角色扮演 | ✅ 角色配置层 | ❌ 通过Prompt间接实现 |
简单示例说明运行机制
简化示意:Agent如何调用LLM class AI玩具Agent: def __init__(self): self.user_memory = {} 用户记忆 self.role_setting = "你是一只名叫'小智'的AI小兔子,喜欢鼓励小朋友" def handle(self, user_id, user_input): 1. 安全审核 if contains_unsafe(user_input): return "这个问题我回答不了哦" 2. 加载记忆 history = self.user_memory.get(user_id, []) 3. 构建上下文并调用LLM prompt = f"{self.role_setting}\n历史对话:{history}\n用户:{user_input}\n小智:" reply = call_llm(prompt) 调用DeepSeek/豆包等大模型 4. 更新记忆 self.user_memory[user_id] = history + [(user_input, reply)] 5. 可选:驱动肢体动作 if "拥抱" in user_input: make_hug_gesture() return reply
五、概念关系与区别总结
一句话概括:Agent是“大脑的调度中心”,LLM是“大脑的思考引擎”——Agent决定何时思考、思考什么、如何行动;LLM负责执行思考这一环节。
两者的逻辑关系清晰:
设计思想 vs 落地技术:Agent代表了一种“自主决策”的设计思想,而LLM是实现这种思想的底层技术之一
整体 vs 局部:Agent是一个完整的控制系统(包含感知→决策→执行闭环),LLM只是其中的推理生成模块
角色定位:Agent是“管理者”,LLM是“执行者”
特别说明:本文主要聚焦于Agent与LLM这两个最核心的概念,它们在AI助手玩具的技术架构中处于支配性地位。其他技术模块(如语音识别ASR、语音合成TTS、动作控制等)虽然同样重要,但属于配套模块,后续专题中会再作深入探讨。
六、代码/流程示例演示
以接入DeepSeek大模型的AI助手玩具为例,展示完整交互流程:
import requests from typing import Dict, List class AICompanionAgent: """AI助手玩具Agent——完整示例""" def __init__(self, api_key: str, toy_role: str): self.api_key = api_key self.role = toy_role 玩具角色设定 self.memory: Dict[str, List[Dict]] = {} 用户记忆库 def add_memory(self, user_id: str, user_msg: str, bot_reply: str): """记忆管理:保存对话历史""" if user_id not in self.memory: self.memory[user_id] = [] self.memory[user_id].append({ "role": "user", "content": user_msg }) self.memory[user_id].append({ "role": "assistant", "content": bot_reply }) 限制记忆长度,防止超长上下文 if len(self.memory[user_id]) > 20: self.memory[user_id] = self.memory[user_id][-20:] def safety_check(self, text: str) -> bool: """安全审核:过滤不适宜儿童的内容""" unsafe_keywords = ["暴力", "色情", "恐怖", "骂人"] return not any(kw in text for kw in unsafe_keywords) def call_llm(self, user_id: str, user_input: str) -> str: """调用大模型API——以DeepSeek为例""" 构建完整提示词(包含角色设定+记忆) system_prompt = f"""你是{self.role},一个专为儿童设计的AI助手玩具。 你需要:1.用温暖、鼓励的语气交流;2.回答要简洁、有趣、适合儿童理解; 3.当孩子提出危险问题时,要引导他询问父母。""" 获取历史对话(最近10轮) history = self.memory.get(user_id, [])[-20:] messages = [{"role": "system", "content": system_prompt}] + history messages.append({"role": "user", "content": user_input}) 调用DeepSeek API response = requests.post( "https://api.deepseek.com/v1/chat/completions", headers={"Authorization": f"Bearer {self.api_key}"}, json={ "model": "deepseek-chat", "messages": messages, "temperature": 0.7, "max_tokens": 150 } ) return response.json()["choices"][0]["message"]["content"] def handle_interaction(self, user_id: str, user_input: str): """
对比新旧实现方式:
| 维度 | 传统规则式(if-else) | Agent + LLM架构 |
|---|---|---|
| 代码量 | 随功能指数增长 | 固定架构,功能通过Prompt扩展 |
| 上下文记忆 | ❌ 不支持 | ✅ 自动管理 |
| 角色一致性 | 手动维护 | 系统Prompt保证 |
| 扩展新功能 | 需改代码 | 改Prompt即可 |
| 安全防护 | 手工过滤列表 | Agent层统一处理 |
七、底层原理/技术支撑点
Agent之所以能“调度”大模型、实现记忆管理与安全防护,背后依赖几个关键的技术基础:
1. 提示工程(Prompt Engineering)
Agent通过精心设计的系统提示词(System Prompt)来“引导”大模型的行为,使大模型输出的内容符合玩具的角色设定和安全规范。提示词中可以嵌入安全约束、输出格式要求、角色性格描述等。
2. 嵌入向量与检索增强生成(RAG)
长期记忆功能的核心技术。Agent将用户的对话内容转换为嵌入向量(Embedding Vector)存储,需要回忆时通过向量相似度检索最相关的历史信息,再连同当前问题一起送给大模型。这种方式使得记忆长度不再受限于大模型的上下文窗口。
3. 端侧推理与知识蒸馏
以DeepSeek-R1为代表的技术路径,通过知识蒸馏将千亿参数模型的核心能力迁移至小型化架构,使得玩具内置的低成本芯片也能运行本地化推理。实验数据显示,经过蒸馏的1.5B参数模型在数学推理任务中的准确率仍能达到原模型的92%,而参数量仅为1/450-38。
4. 多智能体协同(Multi-Agent)
实丰文化最新推出的SF-Hola智能体基于Multi-Agent架构,内置情感陪伴、教育启蒙、心理健康等多场景独立技能模块,无需用户反复触发即可自主响应需求场景,打破传统AI玩具“大模型套壳”的局限-37。多个Agent各司其职、协同工作,实现更精细化的功能分工。
八、高频面试题与参考答案
面试题1:AI玩具中的Agent和LLM有什么区别?请简要说明。
标准答案:
Agent是调度与协调层,负责场景识别、记忆管理、安全防护和模型调度;LLM是推理生成层,负责理解输入并生成回复。二者是“管理者与执行者”的关系。Agent决定“何时调用LLM、调用哪个LLM”,LLM执行Agent交办的生成任务。
踩分点:明确指出分层关系 + 各司其职 + 举例说明。
面试题2:如何解决AI玩具中LLM响应延迟过大的问题?
标准答案:
主要通过四种策略:①分层模型调度——简单问题调用端侧小模型,复杂问题上云端大模型;②端云协同——端侧处理实时性要求高的任务,云端处理复杂推理;③知识蒸馏——将大模型压缩部署至端侧,如DeepSeek-R1蒸馏方案可将延迟控制在100毫秒以内;④预生成缓存——对高频问答预先生成回复,直接命中无需调用模型。
踩分点:多策略组合 + 技术名称 + 量化指标。
面试题3:AI玩具如何实现“记住用户”的功能?
标准答案:
采用“RAG(检索增强生成)+ 向量数据库”方案。具体流程:①将每次对话内容转换为嵌入向量(Embedding)并存储;②用户再次交互时,Agent通过向量相似度检索最相关的历史信息;③将检索结果作为上下文附加到LLM的输入中;④LLM据此生成“有记忆感”的回复。短期记忆通过会话内的消息列表直接维护。
踩分点:RAG概念 + 向量检索 + 短期/长期记忆区分。
面试题4:在AI玩具开发中,如何保障儿童数据安全与内容安全?
标准答案:
内容安全方面:①Agent层设置输入输出双重过滤,使用敏感词库和基于LLM的审核模型;②接入专业内容安全API(如百度、阿里云的内容审核服务)。数据安全方面:①敏感数据本地处理,不上传云端;②若需上传,必须进行匿名化和加密;③遵循GDPR等法规要求,建立明确的隐私政策和用户授权机制;④限制数据保留周期。
踩分点:输入输出双重过滤 + 数据本地化 + 合规要求。
九、结尾总结
回顾核心知识点
Agent是AI助手玩具的“调度中心” :负责感知环境、决策调用、管理记忆、保障安全
LLM是“思考引擎” :执行具体的理解和生成任务,受Agent调度
两者关系:Agent是管理者,LLM是被管理者,协同构成完整的智能交互系统
技术底座:提示工程、RAG向量记忆、知识蒸馏、多智能体协同
关键能力:上下文记忆、安全防护、分层模型调度、端云协同
重点提示与易错点
⚠️ 不要混淆Agent和LLM——面试中常考,记住“Agent管调度、LLM管生成”
⚠️ 不要忽视安全层——AI玩具面向儿童,安全审核不是可选功能而是必选项
⚠️ 端侧推理≠能力差——蒸馏技术让小模型在特定任务上已接近大模型效果
进阶预告
下一篇将深入探讨 “AI玩具中的多模态交互” ——如何让玩具具备“看”和“听”的能力(视觉识别、情绪感知、动作联动),敬请期待。
互动话题:你最近体验过哪款AI助手玩具?它用到了本文提到的哪些技术?欢迎在评论区留言交流!