开篇:AI算命,技术圈的“奇葩”赛道
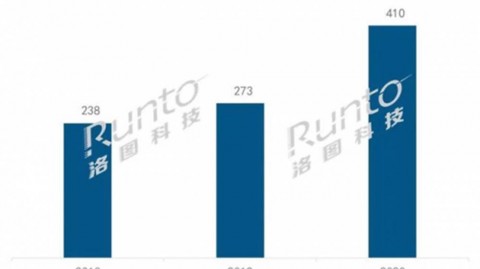
2026年,如果你还没用AI算过命,那你可能真的有点“落伍”了。小红书上“DeepSeek玄学”话题下,近六千条笔记仍在不断刷新;B站的“大众塔罗”直播,一场能吸引上万人在线;而在豆包平台,一个名为“塔罗占卜师”的智能体,日均交互量已超百万-1。数据显示,18至30岁的年轻人中,有60%的人体验过AI算命-1。

但问题来了——很多开发者只会上传几张照片、输入几个八字,让AI出个运势报告,却完全不知道AI是怎么“算”出来的。 面试被问到“RAG是什么”“微调是怎么做的”,瞬间卡壳;想自己开发一个命理类AI应用,又不知道从何下手。
今天这篇文章,我们就来彻底拆解AI算命背后的技术原理。从传统实现的痛点出发,讲清楚大语言模型(LLM, Large Language Model) 的核心工作机制、检索增强生成(RAG, Retrieval-Augmented Generation) 与模型微调(Fine-tuning) 的区别与关联,再奉上一份可运行的代码示例和5道高频面试题,让你一次看懂、记住、能用。
系列预告:本文为“AI应用开发实战”系列第1期,后续将陆续推出RAG深度进阶、Agent智能体构建等内容,欢迎持续关注。
一、痛点切入:为什么需要AI算命技术?
传统方案长什么样?
在没有大模型之前,做一个算命小程序,通常的做法是硬编码规则:
传统算命:纯规则匹配 def fortune_telling(birth_year, birth_month): 干支推算 ganzhi = ((birth_year - 4) % 60, (birth_month - 1) % 12) 嵌套if-else判断吉凶 if ganzhi in ["甲子", "乙丑", "丙寅"]: fortune = "大吉,万事如意" elif ganzhi in ["戊戌", "己亥"]: fortune = "凶,诸事不宜" else: fortune = "平,小心谨慎" return f"{ganzhi}日运势:{fortune}"
传统方案的三宗罪
这种方案存在明显缺陷:
耦合度高:规则和输出强绑定,改一个字就要改代码。
扩展性差:新增一种算命体系(如星座、塔罗),需要全部重写规则逻辑。
缺乏“人味儿”:输出千篇一律,用户一用就腻,完全不像一个“有温度的大师”在跟你对话。
而AI大模型的出现,彻底改变了这一局面。它不再依赖人工预设的if-else规则,而是通过学习海量数据中的语言模式,动态生成自然、多变、有温度的回应。
二、核心概念讲解:大语言模型(LLM)
标准定义
大语言模型(LLM, Large Language Model) :基于Transformer架构,通过海量文本数据训练而成的大规模神经网络模型,核心能力是理解上下文、进行逻辑推理并生成连贯的自然语言。
拆解关键词
“大” :指参数量巨大——数十亿甚至数千亿个参数。这些参数就像模型大脑里的“突触”,存储了它从海量文本中学到的知识。
“语言模型” :本质上是“语言概率模型”。它根据前文,预测下一个词最可能是什么。
Transformer架构:一种基于“自注意力(Self-Attention)”机制的神经网络结构,能够并行处理整段文本,捕捉长距离的词与词之间的依赖关系。
生活化类比
把大语言模型想象成一个“学富五车但从不亲自体验生活的作家” 。它读完了全人类几乎所有的书籍、文章、聊天记录,但它自己从未真正经历过那些事情。当你说“帮我算算明天的运势”,它不会真的去“看天象”,而是回忆所有它读过的文章中,“运势类”文本是怎样的风格、用了哪些词语,然后按照这个模式为你“创作”一篇出来。
作用与价值
LLM解决了传统方案的三大痛点:它不依赖硬编码规则(低耦合),可以回答任意问题(高扩展性),输出多变且风格可调(有“人味儿”)。在AI算命的场景下,LLM扮演的角色就是那个“话多且说得像模像样的算命先生” ——它负责把从各类命理资料里学到的知识,用自然、顺畅的语言讲给用户听。
三、关联概念讲解:检索增强生成(RAG)
标准定义
检索增强生成(RAG, Retrieval-Augmented Generation) :一种将信息检索(Information Retrieval) 与文本生成(Text Generation) 相结合的技术架构。在LLM生成回答之前,RAG先从外部知识库中检索相关内容,再将检索结果“增强”到提示词(Prompt)中,供LLM参考作答。
它与LLM的关系
LLM 是“大脑”,负责组织语言、生成回答。
RAG 是“书童”,负责在回答之前从书架上翻出相关的参考书,递给大脑。
为什么要用RAG?
LLM有一个致命的弱点——幻觉(Hallucination) :在缺乏事实依据的情况下,它仍能生成看似合理但实则错误的内容-24。这在算命领域尤为致命:比如把五行属性张冠李戴,或者凭空编出一本不存在的“古籍”来佐证自己的说法。
RAG的核心价值在于抑制“创造性冲动” :在生成回答前,先实时检索经过筛选与验证的知识库(包括传统算命典籍、专业命理理论等),再基于这些内容进行推演-24。SajuGPT等专业系统已经验证了这一路线的可行性,业界将其视为AI算命从“娱乐导向”迈向“专业辅助工具”的重要一步-24。
简单示例说明
【无RAG】用户问:“2026年属马的运势如何?” LLM自由发挥:一通乱编,可能把虎年运势套在马年上。 【有RAG】用户问:“2026年属马的运势如何?” 1. 检索:从知识库中检索“2026年 属马 生肖运势” 2. 增强:将检索到的内容拼接到提示词中 3. 生成:LLM基于真实资料生成回答
四、概念关系与区别总结
| 维度 | LLM(大语言模型) | RAG(检索增强生成) |
|---|---|---|
| 本质 | 生成模型 | 架构范式 |
| 角色 | 大脑(生成语言) | 书童(提供资料) |
| 知识来源 | 训练数据(预训练时学到的) | 外部知识库(实时检索) |
| 优势 | 语言流畅、覆盖广 | 可追溯、准确率高 |
| 劣势 | 幻觉问题、知识截止 | 依赖库质量、有延迟 |
一句话概括:LLM是“怎么说”的语言发动机,RAG是“说什么”的资料检索器——LLM负责表达,RAG负责确保表达有依据。
五、代码示例:用Python+LangChain构建一个简单的AI命理助手
下面我们搭建一个最小可行的AI命理Agent,让你直观感受LLM是如何“算”的。
环境准备
pip install langchain langchain-community langchain-openai python-dotenv完整代码
import os from dotenv import load_dotenv from langchain_openai import ChatOpenAI from langchain.agents import create_tool_calling_agent, AgentExecutor from langchain.tools import tool from langchain.memory import ConversationBufferMemory from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder load_dotenv() ================= 1. 定义工具 ================= @tool def get_daily_horoscope(zodiac: str) -> str: """获取指定星座的当日运势""" 实际项目中可以调用真实API horoscopes = { "白羊座": "今日行动力强,但注意控制脾气", "金牛座": "财运不错,适合稳健投资", "双子座": "沟通顺畅,适合社交" } return horoscopes.get(zodiac, "今日运势平稳,顺其自然即可") @tool def get_lucky_number(zodiac: str) -> str: """获取幸运数字""" numbers = { "白羊座": "7", "金牛座": "3", "双子座": "5" } return f"{zodiac}的幸运数字是:{numbers.get(zodiac, '6')}" tools = [get_daily_horoscope, get_lucky_number] ================= 2. 初始化LLM ================= llm = ChatOpenAI( model="gpt-3.5-turbo", temperature=0.7 控制输出的随机性:0→确定性,1→创造性 ) ================= 3. 配置Prompt模板 ================= prompt = ChatPromptTemplate.from_messages([ ("system", "你是一位专业的星座命理师,说话风格温和,善于给人心理安慰。"), MessagesPlaceholder(variable_name="chat_history"), ("human", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]) ================= 4. 配置记忆 ================= memory = ConversationBufferMemory( memory_key="chat_history", return_messages=True ) ================= 5. 创建并运行Agent ================= agent = create_tool_calling_agent(llm, tools, prompt) agent_executor = AgentExecutor( agent=agent, tools=tools, memory=memory, verbose=True 打印思考过程 ) 运行示例 if __name__ == "__main__": print(agent_executor.invoke({"input": "我是白羊座,今天运势如何?"})) print(agent_executor.invoke({"input": "那我的幸运数字呢?"})) 能记住你是白羊座
关键步骤注释说明
| 步骤 | 代码位置 | 关键点 |
|---|---|---|
| 1. 定义工具 | @tool 装饰器 | Agent能够“做事”的接口,比如查运势、算数字 |
| 2. 初始化LLM | ChatOpenAI | temperature控制创造力高低,算命场景推荐0.7左右 |
| 3. Prompt模板 | ChatPromptTemplate | 给模型设定“人设”和行为规范 |
| 4. 配置记忆 | ConversationBufferMemory | 让Agent记得之前聊过什么,实现多轮对话 |
| 5. Agent执行器 | AgentExecutor | 自动完成“思考→选择工具→调用→回答”的循环 |
执行流程示意
用户输入:"我是白羊座,今天运势如何?" ↓ LLM判断:需要调用工具来获取运势 ↓ Agent执行:调用 get_daily_horoscope("白羊座") ↓ LLM再次推理:将工具返回结果整理成自然语言 ↓ 输出:"白羊座的朋友,今日行动力强,但注意控制脾气哦!"
六、底层原理与技术支撑
AI算命的底层并非玄学,而是一套严谨的技术栈:
Transformer架构:大语言模型的基础,其核心是“自注意力机制”——让模型在处理一句话时,能够动态判断哪些词之间关系更紧密。这是LLM能理解上下文的关键。
Embedding嵌入技术:将“八字”“星座”“五行”等离散的玄学符号,转化为高维空间中的连续向量,让计算机能够“理解”这些符号之间的相似关系。
RAG架构:向量检索 + LLM生成。先将命理知识库中的文档转换为向量并存储,用户提问后,检索最相似的文档片段,再将结果注入Prompt。
微调(Fine-tuning) :在通用大模型的基础上,用命理领域的数据继续训练一小段时间,让模型“学会”命理术语和推断逻辑。借助Google Colab的免费GPU和Unsloth等工具,零成本也能完成微调-60。
Agent框架(如LangChain) :为LLM提供“工具调用”能力,让模型能够主动查黄历、搜资料、调用API,而不是凭空瞎编。
七、高频面试题与参考答案
1. 大语言模型是如何实现“算命”功能的?
参考答案(层层递进,易背诵):
本质:大语言模型并不具备真正的“预测”能力。它的算命功能本质上是模式识别 + 语言生成。
三层机制:
语义解析层:通过预训练模型理解用户输入的隐含需求;
知识检索层:从知识库或检索增强生成(RAG)中获得依据;
生成控制层:在设定的“人设”和风格约束下,生成符合命理语境的文本。
结论:AI算命是“统计意义上的模仿”,而非因果推理。
2. RAG和Fine-tuning在AI算命场景中有什么区别?如何选择?
参考答案:
| 对比维度 | RAG | Fine-tuning |
|---|---|---|
| 核心逻辑 | 实时检索外部知识库 | 将知识训练进模型参数 |
| 知识更新 | 实时,改库即可 | 需重新训练 |
| 成本 | 低(无需训练) | 高(需要GPU算力) |
| 可解释性 | 强(可溯源到原文) | 弱(知识“融化”在参数中) |
选择建议:
需要实时更新(如每日运势)→ 选RAG
需要改变模型风格(如让模型更像某位命理大师)→ 选Fine-tuning
预算有限的个人开发者:先用RAG;企业级应用:两者结合
3. 如何解决AI算命中的“幻觉”问题?
参考答案(三层次方案):
架构层面:采用RAG架构,让模型回答前先检索可信知识库,减少臆测空间;
数据层面:构建高质量、经过校验的命理数据集,排除低质量或错误信息;
控制层面:调低
temperature参数(如0.3~0.5),限制模型输出的随机性,提高确定性。
4. 训练一个AI算命模型需要什么数据?如何获取?
参考答案:
数据类别:
命理典籍类:《易经》《渊海子平》《三命通会》等经典文本
命理案例类:八字+真实事件的对照数据
命理师语料类:专业命理师的对话记录
获取途径:
开源数据集:ModelScope、Kaggle等平台(如“算命数据集”约699KB)
合成数据:用GPT-4等模型生成模拟数据(需人工校验)
公开爬取:合规采集命理论坛、知识问答平台内容
5. 为什么AI算命会让人觉得“很准”?
参考答案(心理学视角 + 技术分析):
从心理学角度看,这是巴纳姆效应(Barnum Effect) ——人们很容易相信那些笼统的、普遍性的人格描述,并认为它准确地揭示了自己独一无二的特点-1。
从技术角度看,LLM的训练数据中包含了大量人类情感表达和性格描述的文本模式,它能通过统计学习“掌握”那些最容易引起共鸣的表达方式。同时,AI没有人类算命师的道德包袱,更容易说出用户“想听到的话”,这进一步放大了“准”的感觉-5。
八、结尾总结
今天我们围绕AI算命这一话题,拆解了以下核心知识点:
LLM的本质:基于Transformer架构的语言概率模型,负责“怎么说”;
RAG的作用:检索增强生成,负责“说什么有依据”,有效抑制幻觉;
实现路径:Agent工具调用 + Prompt工程 + 记忆管理,构成了一个完整的AI命理助手;
底层技术:Embedding、RAG、Fine-tuning、LangChain各司其职,共同支撑上层应用;
面试要点:5道高频题的参考答案,建议重点记忆RAG vs Fine-tuning对比表和幻觉解决三层次方案。
易错点提醒:很多人误以为AI算命靠的是“算命算法”本身,实际上它依赖的是模式识别、RAG检索和生成控制三层机制协同工作。
预告:下一篇我们将深入讲解RAG架构的完整工程实现,包括向量数据库选型、文档分块策略、检索优化技巧,以及如何从零搭建一个可上线的知识库问答系统。感兴趣的朋友记得关注!
参考文献:本文技术内容参考了CSDN、RedNet、CSDN等平台公开技术文章及行业报道-1-24-55。